重要 2023 年秋の時点で、新しい Personalizer リソースは作成できなくなりました。 このリポジトリは、Personalizer リソースが既にある場合にのみ参照として使用してください。
この演習では、Visual Studio Code で Azure AI Personalizer とノートブックを使用して、学習ループをシミュレートします。
Azure portal を使用して Azure AI Personalizer リソースを作成する
-
Azure portal で、Azure AI サービスを検索します。 次に、結果一覧の [Personalizer] で [作成] を選択します。
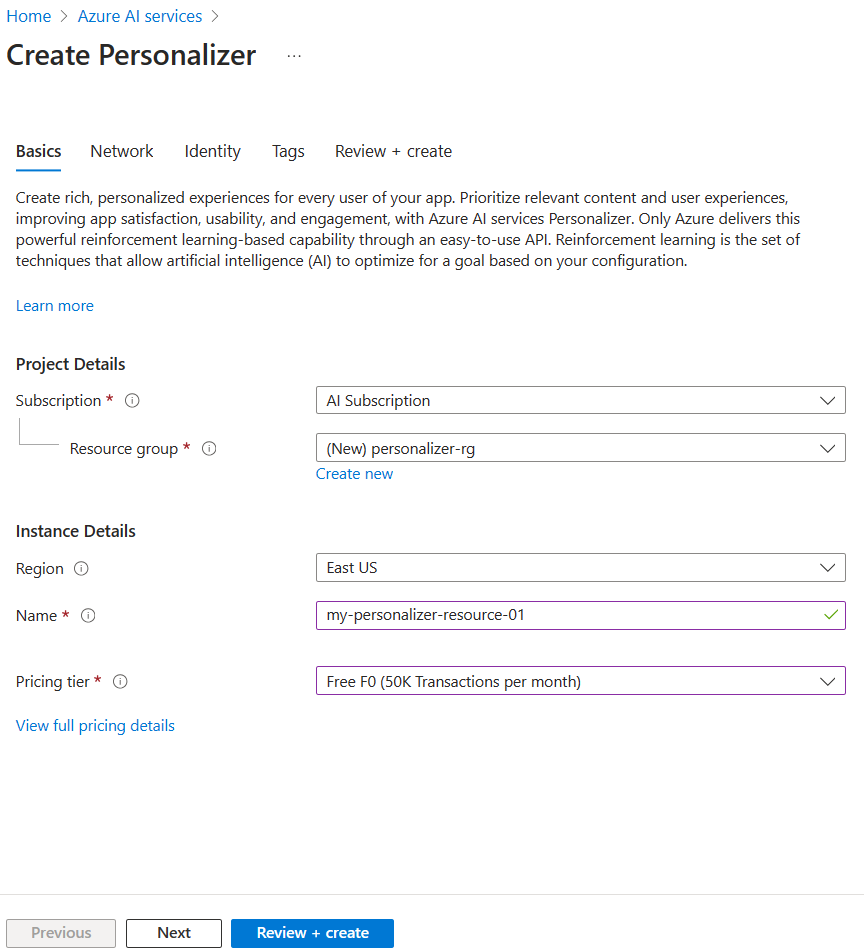
- サブスクリプションを選択し、リソース グループ名とリソースの名前を入力します。 価格レベルとして、[Free F0] を選択します。
- [確認および作成] を選んで選択内容を確認してから、[作成] を選択してリソースを作成します。
-
新しく作成した Azure AI Personalizer リソースに移動し、[キーとエンドポイント] ペインでキーとエンドポイントをコピーして、後で使うために安全などこかに貼り付けます。
![[キーとエンドポイント] ペインを示すスクリーンショット。](/mslearn-ai-services.ja-jp/Instructions/media/ai-personalizer/copy-key-endpoint.png)
- ナビゲーション ウィンドウで [セットアップ] を選択し、[報酬の待機時間] を 10 分に設定し (まだ設定されていない場合)、[モデルの更新頻度] を 15 秒に設定します。
- [保存] を選択します。
ノートブックを設定する
- Visual Studio Code エディターで、Ctrl + Shift + P キーを押し、[作成: 新しい Jupyter Notebook] を選択します。
- 使用しているデバイスにファイルを保存し、my-notebook という名前を付けます。
-
ここで、必要な拡張機能をインストールする必要があります。 ノートブックの右上にある [カーネルの選択] を選びます。 次に、[Install/Enable suggested extensions](推奨される拡張機能のインストール/有効化) を選択します。
[!NOTE] 以前にこれを既に行っている場合は、このオプションは表示されず、この手順を省略できます。
- 拡張機能がインストールされるまで待ってから、表示されるドロップダウンで [Python 環境…] を選択します。
- 次に、最も推奨される環境を選択します。
データを準備する
この演習の目的では、Azure AI Personalizer の基本データとして使用できるユーザーの一覧とコーヒー製品の一覧を作成します。
-
次の JSON コードを空のファイルにコピーし、そのファイルをノートブック ファイルと同じフォルダーに
users.jsonとして保存します。{ "Alice": { "Sunny": { "Morning": "Cold brew", "Afternoon": "Iced mocha", "Evening": "Cold brew" }, "Rainy": { "Morning": "Latte", "Afternoon": "Cappucino", "Evening": "Latte" }, "Snowy": { "Morning": "Cappucino", "Afternoon": "Cappucino", "Evening": "Cappucino" } }, "Bob": { "Sunny": { "Morning": "Cappucino", "Afternoon": "Iced mocha", "Evening": "Cold brew" }, "Rainy": { "Morning": "Latte", "Afternoon": "Latte", "Evening": "Latte" }, "Snowy": { "Morning": "Iced mocha", "Afternoon": "Iced mocha", "Evening": "Iced mocha" } }, "Cathy": { "Sunny": { "Morning": "Latte", "Afternoon": "Cold brew", "Evening": "Cappucino" }, "Rainy": { "Morning": "Cappucino", "Afternoon": "Latte", "Evening": "Iced mocha" }, "Snowy": { "Morning": "Cold brew", "Afternoon": "Iced mocha", "Evening": "Cappucino" } }, "Dave": { "Sunny": { "Morning": "Iced mocha", "Afternoon": "Iced mocha", "Evening": "Iced mocha" }, "Rainy": { "Morning": "Latte", "Afternoon": "Latte", "Evening": "Latte" }, "Snowy": { "Morning": "Cappucino", "Afternoon": "Cappucino", "Evening": "Cappucino" } } } -
次に、以下のコードをコピーし、
coffee.jsonというファイルに保存します。[ { "id": "Cappucino", "features": [ { "type": "hot", "origin": "kenya", "organic": "yes", "roast": "dark" } ] }, { "id": "Cold brew", "features": [ { "type": "cold", "origin": "brazil", "organic": "yes", "roast": "light" } ] }, { "id": "Iced mocha", "features": [ { "type": "cold", "origin": "ethiopia", "organic": "no", "roast": "light" } ] }, { "id": "Latte", "features": [ { "type": "hot", "origin": "brazil", "organic": "no", "roast": "dark" } ] } ] -
次のコードをコピーしてファイルに貼り付け、
example-rankrequest.jsonとして保存します。{ "contextFeatures": [], "actions": [], "excludedActions": [], "eventId": "", "deferActivation": false }
エンドポイントとキーを設定する
-
必要なモジュールを組み込むために、ノートブックの上部に次のコードを追加します。
import json import matplotlib.pyplot as plt import random import requests import time import uuid import datetime -
セルを選択し、セルの左側にある実行ボタンを選択します。
[!NOTE] 新しいセルを作成するたびに、実行ボタンを選択します。 ipykernel パッケージのインストールを求めるメッセージが表示されたら、[インストール] を選択します。
-
ノートブックの上部にある [+ コード] を選択して、新しいコード セルを作成します。 次のコードを追加します。
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values. personalization_base_url = "<your-endpoint>" resource_key = "<your-resource-key>" -
personalization_base_url 値をコピーしたエンドポイントに置き換え、resource_key 値を、使用するキーに置き換えます。
反復を追跡する
-
次に、後で使う反復関数の開始と終了の時刻をメモするのに役立つコードを作成します。 新しいセルに次のコードを追加します。
# Print out current datetime def currentDateTime(): currentDT = datetime.datetime.now() print (str(currentDT)) # ititialize variable for model's last modified date modelLastModified = "" def get_last_updated(currentModifiedDate): print('-----checking model') # get model properties response = requests.get(personalization_model_properties_url, headers = headers, params = None) print(response) print(response.json()) # get lastModifiedTime lastModifiedTime = json.dumps(response.json()["lastModifiedTime"]) if (currentModifiedDate != lastModifiedTime): currentModifiedDate = lastModifiedTime print(f'-----model updated: {lastModifiedTime}') -
新しいコードを追加したら、必ず新しいセルを実行してください。
ポリシーとサービスの構成を取得する
-
次に、ポリシーとサービスの構成を取得してサービスの状態を検証する必要があります。 これを行うには、新しいセルに次のコードを追加します。
def get_service_settings(): print('-----checking service settings') # get learning policy response = requests.get(personalization_model_policy_url, headers = headers, params = None) print(response) print(response.json()) # get service settings response = requests.get(personalization_service_configuration_url, headers = headers, params = None) print(response) print(response.json()) -
必ず新しいコード セルを実行してください。
このコードは、サービス API を 2 回呼び出す関数で構成されます。 この関数を呼び出すと、応答を使用してサービスの値が返されます。
呼び出しの URL を設定して JSON ファイルを読み込む
次に、以下のためのコードを追加します。
- REST 呼び出しで使用される URL を構築する
- Personalizer リソースのキーを使用してセキュリティ ヘッダーを設定する
- Rank イベント ID のランダム シードを設定する
- JSON データ ファイルを読み込む
- get_last_updated メソッドを呼び出す (出力例では、学習ポリシーが削除されています)
- get_service_settings メソッドを呼び出す
-
これを行うには、次のコードを新しいセルに追加して実行します。
# build URLs personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank" personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward" personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties" personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy" personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service" headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'} # context users = "users.json" # action features coffee = "coffee.json" # empty JSON for Rank request requestpath = "example-rankrequest.json" # initialize random random.seed(time.time()) userpref = None rankactionsjsonobj = None actionfeaturesobj = None with open(users) as handle: userpref = json.loads(handle.read()) with open(coffee) as handle: actionfeaturesobj = json.loads(handle.read()) with open(requestpath) as handle: rankactionsjsonobj = json.loads(handle.read()) get_last_updated(modelLastModified) get_service_settings() print(f'User count {len(userpref)}') print(f'Coffee count {len(actionfeaturesobj)}') -
この呼び出しからは次のような応答が返されます。
-----checking model <Response [200]> {'creationTime': '2023-09-22T14:58:45+00:00', 'lastModifiedTime': '2023-09-22T14:58:45+00:00'} -----model updated: "2023-09-22T14:58:45+00:00" -----checking service settings <Response [200]> {'name': '917554355a3347a1af3d2935d521426a', 'arguments': '--cb_explore_adf --epsilon 0.20000000298023224 --power_t 0 -l 0.001 --cb_type mtr -q ::'} <Response [200]> {'rewardWaitTime': 'PT10M', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': 'PT15S', 'logRetentionDays': 90, 'lastConfigurationEditDate': '2021-01-01T00:00:00', 'learningMode': 'Online'} User count 4 Coffee count 4 -
応答コードは、呼び出しが成功したことを示す
<Response [200]>であるはずです。 rewardWaitTime は 10 分として表示され、modelExportFrequency は 15 秒である必要があります。
Azure portal でグラフを設定する
このコードで API に要求を行います。 要求に適したメトリックを取得するには、Azure portal でメトリック グラフを作成します。
-
Azure portal で、Azure AI Personalizer リソースに移動します。
-
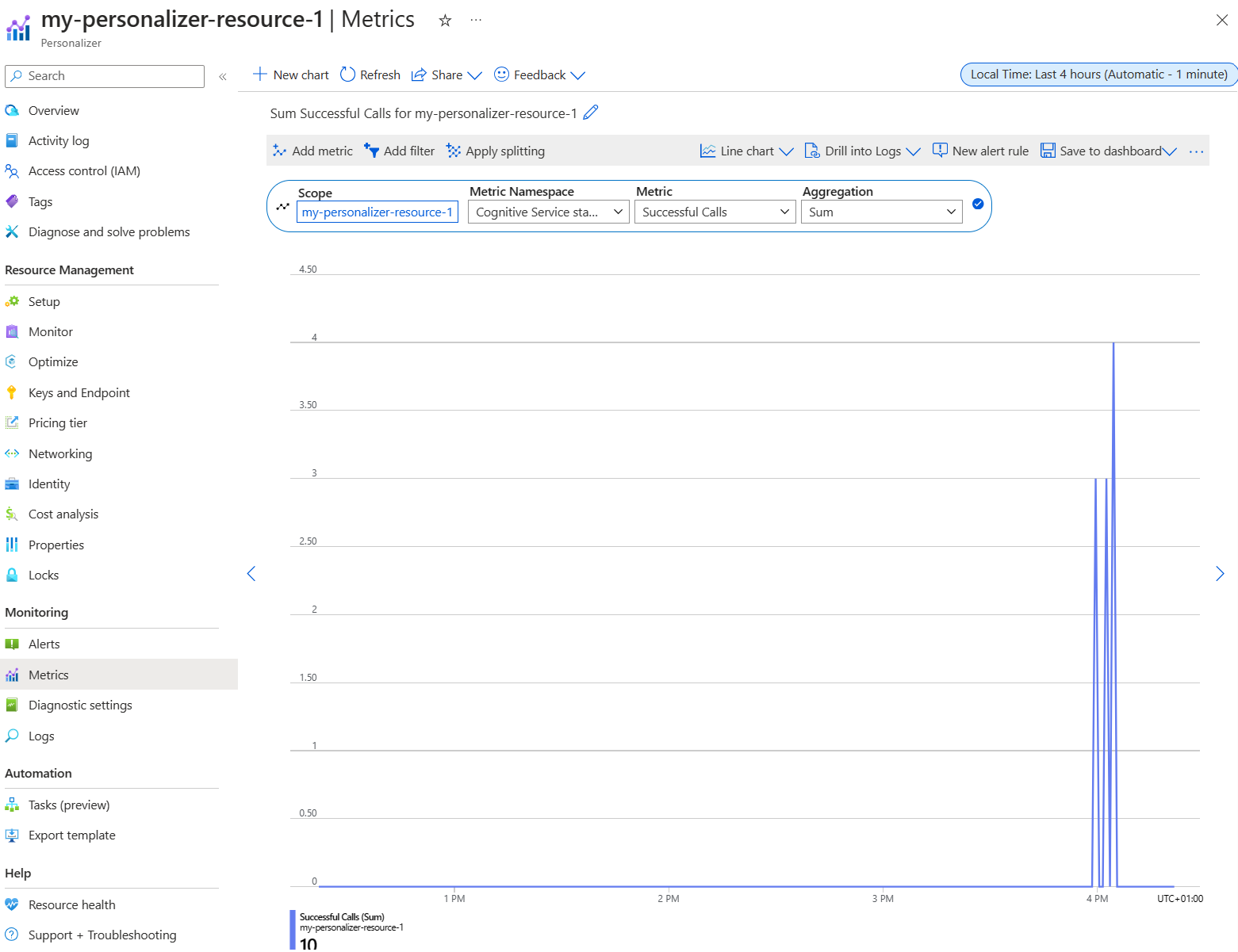
ナビゲーション ウィンドウで [監視] の [メトリック] を選択します。
-
[スコープ] と [メトリック名前空間] は既に設定されています。 必要なのは、[メトリック] に [成功した呼び出し]、[集計] に [合計] を選択することだけです。
-
時間フィルターを過去 4 時間に変更します。
一意のイベント ID を作成する
次に、順位の API 呼び出しごとに一意の ID を生成するコードを追加します。 この ID を使用して、要求の順位と報酬の呼び出し情報を識別します。
-
これを行うには、ノートブックに新しいコード セルを作成し、以下を追加します。
def add_event_id(rankjsonobj): eventid = uuid.uuid4().hex rankjsonobj["eventId"] = eventid return eventid -
新しいコード セルを実行することを忘れないでください。
[!NOTE] 実際のシナリオでは、これを購入のトランザクション ID などに設定します。
ユーザー、時間帯、天気を取得する
これで、次のための関数を追加できるようになりました。
- 一意のユーザー、時間帯、天気の組み合わせを選択する。
- 選択したそれらの項目を、呼び出しを介して Rank API に送信される JSON オブジェクトに追加します。
これを行うには、次のコードを新しいセルに追加して実行します。
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
コーヒー データを追加する
次に、コーヒー製品の一覧全体を JSON オブジェクトに取得し、Rank API に送信する関数を作成します。
これを行うには、次のコードを新しいセルに追加して実行します。
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
予測を既知のユーザーの好みと比較する
これで、特定のコーヒーに関するユーザーの好みと Azure AI Personalizer が提案するものを天気や時間帯などの詳細を考慮して比較する関数を作成できます。
-
これを行うには、新しいセルを作成し、次のコードを追加して実行します。
def get_reward_from_simulated_data(name, weather, timeofday, prediction): if(userpref[name][weather][timeofday] == str(prediction)): return 1 return 0 -
この関数は、Rank API が呼び出されるたびに実行されることを想定したものです。 提案が一致した場合は、応答でスコア
1が返されます。 そうでない場合は、0が返されます。
Rank と Reward の API の呼び出しを含むループを作成する
これまでのセルは、ループのノートブックを設定するために使用されます。 次に、ループを構成します。 このループには、ノートブックでの処理の本体が含まれます。 ランダムなユーザーを取得し、コーヒー リストを取得して、両方を Rank API に送信します。 Azure AI Personalizer からの予測とそのユーザーの既知の好みを比較し、報酬を Azure AI Personalizer に再び送信します。
ループを作成するには、次のコードを新しいセルに追加して実行します。
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)*10
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
関数が Rank API に送信する JSON 構造体の例を次に示します。
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of the coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Rank API からの応答は、次のような構造の応答になります。
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
ループの反復ごとに、ランダムに選択されたユーザー、天気、時間帯と、適切に決定された報酬が表示されます。
1 Alice Rainy Morning Latte 1
1 の報酬は、Azure AI Personalizer リソースで、この特定の組み合わせのユーザー、天気、時間帯に適したコーヒーの種類が選択されたことを意味します。
ループを実行してグラフの結果を表示する
Azure AI Personalizer でモデルを作成するためには、Rank API と Reward API への数千回の呼び出しが必要とされます。 ここでは、設定した反復回数だけループを実行します。
-
これを行うには、新しいコード セルを作成し、次のコードを追加して実行します。
# max iterations num_requests = 150 # check last mod date N% of time - currently 10% lastModCheck = int(num_requests * .10) jsonTemplate = rankactionsjsonobj # main iterations [count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate) - Azure portal のメトリック グラフを頻繁に更新して、サービスに対する呼び出しの合計を確認します。
-
このイベントはしばらくの間実行される可能性があります。 完了するまでノートブックを閉じないでください。 約 20,000 回の呼び出し (ループを反復するたびに順位と報酬の呼び出しが 1 回) が行われたら、ループは終了します。
-
次に、順位イベントのバッチと、各バッチに対して行われた正しい推奨の数をプロットするグラフをノートブックで作成します。 そのためには、次のコードを新しいセルに追加して実行します。
def createChart(x, y): plt.plot(x, y) plt.xlabel("Batch of rank events") plt.ylabel("Correct recommendations per batch") plt.show() createChart(count,rewards) -
ノートブックでグラフが作成されます。
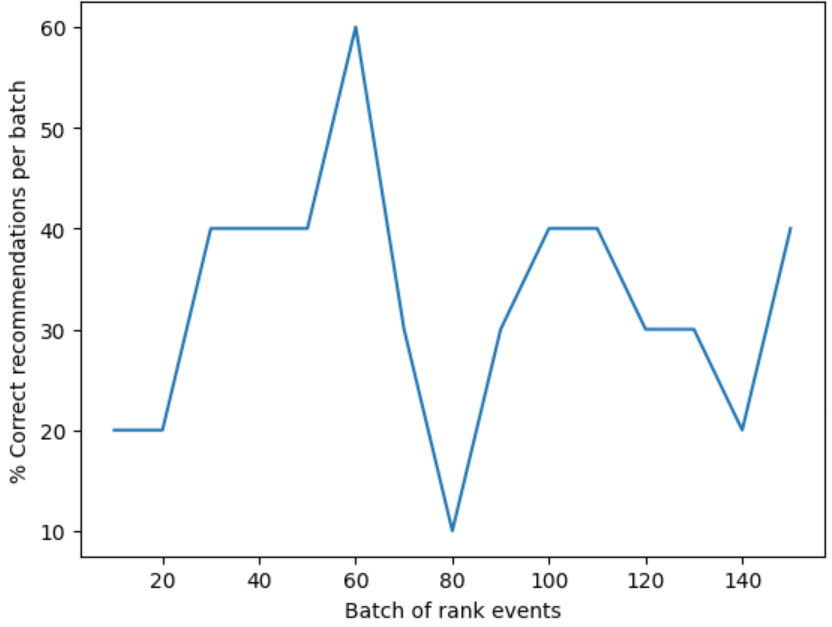
ヒント: テストが完了すると、ループは平均して 100% から探索値 (既定では 20%) を引いた割合で正しい推奨事項を作成する必要があるため、ここでの目標レートは 80% です。 これを得る方法は、反復を少なくとも 10,000 回に増やすことです。
グラフには、既定の学習ポリシーに基づいて、モデルの成功の度合いが表示されます。 このグラフは、学習ポリシーを改善できることを示しています。 これを行うには、評価の実行後にポリシーを変更します。
オフライン評価を実行する
[!NOTE] この演習のこのセクションは省略可能です。これは、Azure AI Personalizer リソースに対して少なくとも 50,000 回の呼び出しを行った後にのみ実行できるためです。 ただし、リソースに対する呼び出しが 50,000 回に達したら、このセクションに戻ってくることができます。
50,000 回以上の呼び出しでオフライン評価を実行して、Azure AI Personalizer リソースの学習ポリシーを改善できます。
- Azure portal で、Azure AI Personalizer リソースの [最適化] ペインに移動し、[評価の作成] を選択します。
-
評価名を指定し、ループ評価の開始と終了の日付範囲を選択します。 この日付範囲には、評価の対象とする日のみを含める必要があります。
-
[評価の開始] を選択して評価を開始します。
-
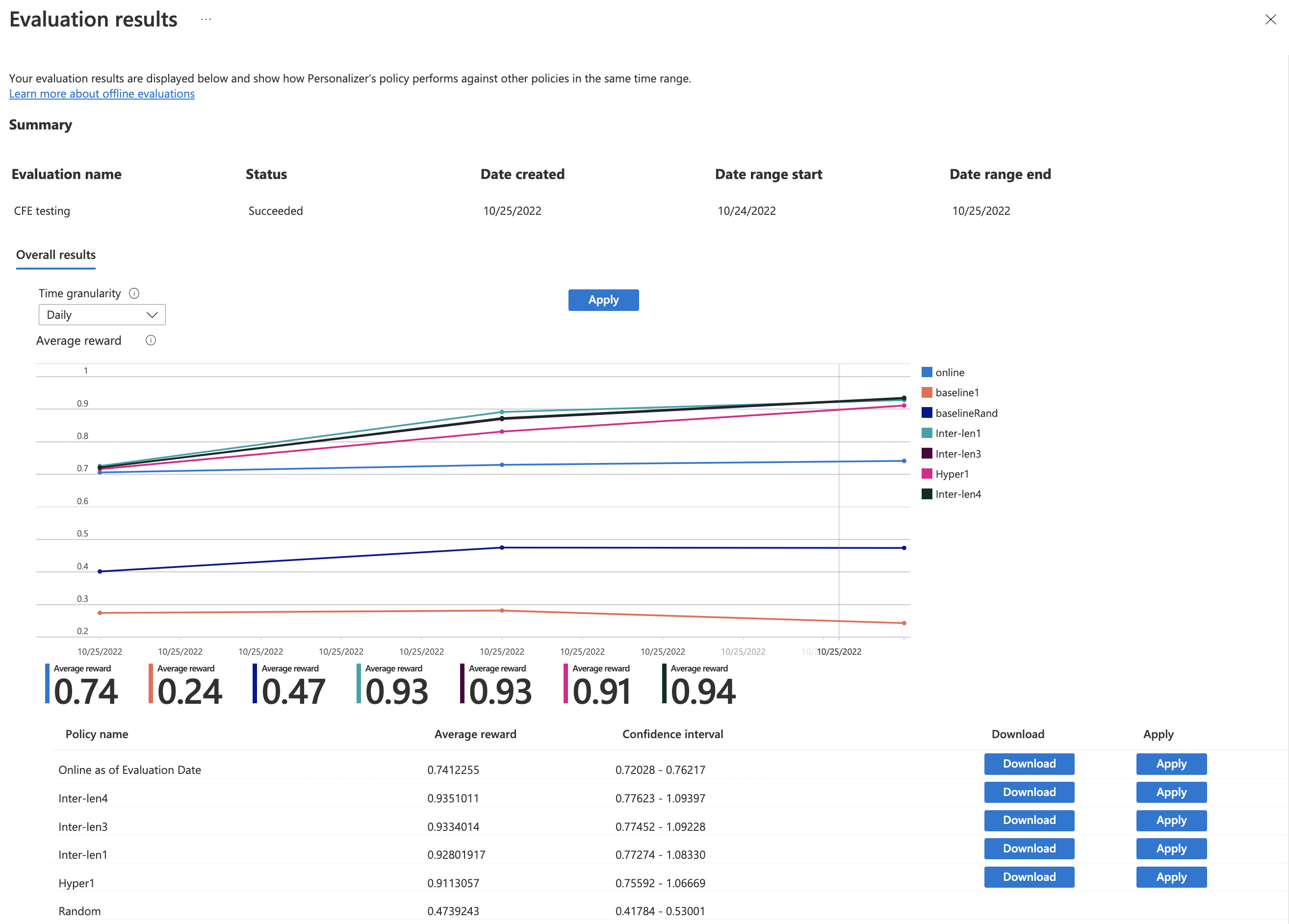
評価が完了したら、それを [最適化] ペインの評価の一覧から選択します。 その後、平均報酬や信頼区間などの詳細に基づいて、学習ポリシーのパフォーマンスを確認できます。
-
次のようないくつかのポリシーが表示されます。
- オンライン - Azure AI Personalizer の現在のポリシー。
- Baseline1 - アプリのベースライン ポリシー。
- BaselineRand - ランダムにアクションを実行するポリシー。
- Inter-len# または Hyper# - 最適化の検出によって作成されたポリシー。
- モデルを最適に向上させるポリシーの [適用] を選択します。
リソースをクリーンアップする
このラボで作成した Azure リソースを他のトレーニング モジュールに使用していない場合は、それらを削除して、追加料金が発生しないようにすることができます。
-
https://portal.azure.comで Azure portal を開き、上部の検索バーで、このラボで作成したリソースを検索します。 -
[リソース] ページで [削除] を選択し、指示に従ってリソースを削除します。 または、リソース グループ全体を削除して、すべてのリソースを同時にクリーンアップすることもできます。